

Automating Earned Value Management (EVM) for enterprise schedule controls
On large-scale industrial and infrastructure projects, schedule performance isn't just a progress metric—it's a direct driver of cash flow, contractual compliance, and project viability. Yet most project teams still update their schedules manually in Microsoft Project, export data to spreadsheets, and calculate Earned Value Management (EVM) metrics by hand. The result is schedule data that is perpetually two weeks stale and EVM reports that consume more engineering time to produce than they save.
This guide breaks down the specific failures of manual schedule tracking, and how an integrated Schedule Control Engine transforms EVM from a reporting exercise into a real-time decision-support system.
The three critical problems with manual schedule tracking
Stale data kills proactive decision-making — Manual schedule updates happen weekly at best. By the time a project manager identifies a negative Schedule Performance Index (SPI) trend, the project has already consumed three weeks of float. Automated EVM requires live data tied to actual field progress—not a once-a-week update session.
Manual EVM calculation introduces compounding errors — Earned Value and Schedule Variance involve multi-step calculations across thousands of work packages. A single formula error in a shared spreadsheet propagates incorrect metrics to every downstream report, and nobody catches it until a client review exposes the discrepancy.
Resource drain on project controls engineers — Generating a weekly EVM report and S-curve manually on a complex project consumes 4–8 hours of a project controls engineer's time. Multiplied across a 24-month project, that's a significant portion of the controls budget spent on data assembly rather than analysis.
The Schedule Control Engine: Core capabilities
The platform's Schedule Control Engine is built around seven integrated capabilities that automate the EVM lifecycle from schedule import to predictive forecasting.
Native Microsoft Project XML import
Rather than forcing teams to abandon existing schedule workflows, the engine imports .mpp files directly via XML export. The structured data model preserves WBS hierarchy, task dependencies, resource assignments, and baseline dates—so the platform becomes the analytics layer on top of existing scheduling tools rather than a replacement.
Automated EVM calculation engine
Planned Value (PV), Earned Value (EV), Schedule Variance (SV) and Schedule Performance Index (SPI) are calculated automatically on every data refresh. No manual formula maintenance, no spreadsheet version conflicts—the metrics are always current and consistent.
Dynamic S-curve generation
S-curves are generated automatically from schedule data, showing cumulative planned versus actual progress over time. For project owners and lenders, this provides the standardized performance visualization required by most capital project reporting frameworks without requiring a separate graphics tool.
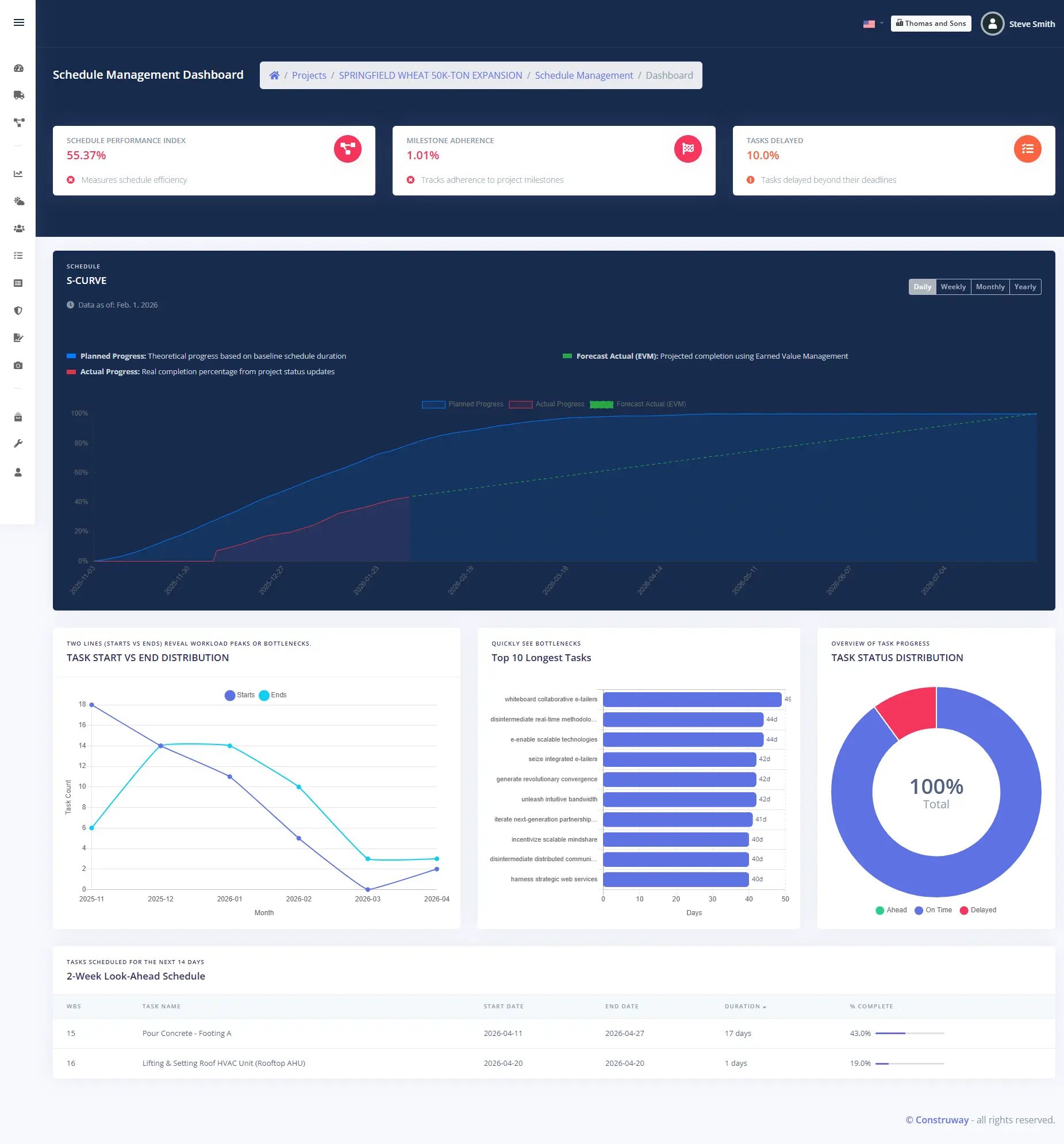
Predictive completion forecasting
The engine calculates Time Estimate at Completion (EAC(t)) using SPI-based forecasting, projecting the expected finish date from current schedule performance trends. This gives project directors the quantitative basis to distinguish between recoverable schedule slippage and structural delays that require scope adjustment or resource reallocation before the contractual completion date is at risk.
Look-ahead scheduling
A configurable rolling look-ahead window (typically 3–6 weeks) extracts the near-term work plan from the master schedule. This bridges the gap between the long-range Gantt chart and field execution—giving superintendents a daily/weekly view of what must be resourced and mobilized in the immediate term.
Baseline adherence tracking
Every schedule update is compared against the locked baseline. Float consumption, slippage on critical path activities, and milestone date drift are automatically flagged. This enforces schedule discipline and provides an early warning system before critical path compression becomes a crisis.
WBS-level drill-down
EVM metrics are available at every level of the Work Breakdown Structure. A portfolio-level view shows overall project health; a discipline-level view identifies which areas are driving schedule variance; a work package view provides the granular data needed for field crew deployment decisions.
Core data model for schedule intelligence
The platform's schedule data model is designed to support both current-cycle reporting and longitudinal analysis across the project lifecycle.
Activity-Level Performance Records — Each schedule activity carries a complete history of planned versus actual start/finish dates, percent complete progression, and resource consumption. This enables earned schedule analysis and identifies which activity types consistently underperform against plan.
Baseline Version Control — Multiple baseline versions are stored with timestamps, enabling before-and-after analysis when scope changes or contract amendments alter the performance measurement baseline.
Integrated Progress Periods — Each data refresh is stored as a distinct progress period, enabling trend analysis across reporting cycles and providing the time-series data required for Schedule Risk Analysis.
Predictive forecasting: From reactive to proactive controls
The highest-value capability of automated EVM is not the metrics themselves—it is the ability to forecast future performance before problems become visible in the field.
When the SPI falls below a defined threshold across the global schedule, the platform flags the divergence and recalculates the expected completion date by dividing actual progress by planned progress to derive the current performance ratio, then applying it to adjust the remaining duration. Project managers can consult this updated forecast and intervene with resource reallocation or look-ahead adjustments before the schedule variance becomes a contractual issue—not after the client identifies it in a monthly progress meeting.
This is the fundamental shift that automated EVM enables: from documenting what happened to predicting what will happen if current trends continue.
Conclusion
Manual schedule tracking and EVM calculation is not just inefficient—it is structurally incompatible with the decision-making speed that complex industrial projects require. By the time manual reports are assembled and distributed, the conditions they describe have already changed.
An automated Schedule Control Engine with native MS Project integration, real-time EVM metrics, dynamic S-curves, and predictive forecasting transforms schedule management from a reporting burden into a live decision-support system that protects margins and enables proactive project leadership.
Ready to automate your project controls? Book a demo to see the Schedule Control Engine live.
Frequently asked questions
EVM is a project performance measurement methodology that tracks schedule progress against a baseline. By comparing Planned Value (what should have been done) with Earned Value (what was done), it calculates Schedule Variance (SV) and Schedule Performance Index (SPI = actual ÷ planned) — giving project teams a quantitative measure of how efficiently the schedule is being executed.
Automated EVM eliminates the 4–8 hour weekly reporting cycle that manual systems require. By continuously calculating metrics from live schedule data, project managers receive early warning signals — such as declining SPI trends — in time to intervene before schedule variance becomes a contractual issue.
No. The Schedule Control Engine imports MS Project files via standard XML export, preserving the WBS structure, dependencies, and resource data. The platform functions as the analytics and visualization layer on top of existing scheduling workflows.
Related articles
Deep dives into the tools and strategies that keep capital projects on track.




